SUPPORT VECTOR MACHINE
Linear SVM(support vector machine)
Hyperplane
hyperplane은 다음과 같이 정의된다
\(\lbrace \vec{x} \mid \vec{w}^{T}\vec{x}=b \rbrace\) where $\vec{x} \in \mathbb{R}^{n}$ and $b \in \mathbb{R}$
다시말해서 위의 등식을 만족시키는 $\vec{x}$의 집합이다.
예를들어 $\vec{x} \in \mathbb{R}^{2}$라면,
\(\lbrace (x_{1},x_{2}) \mid ax_{1}+bx_{2}=b \rbrace\)를 만족하는 해집합 $(x_{1},x_{2})$은 $\mathbb{R}^{2}$을 가르는 직선형태를 띌 것이다. (마찬가지로 $\mathbb{R}^{3}$라면 $\vec{x}$의 해집합은 평면)
일반화 해서 $\vec{x} \in \mathbb{R}^{n}$에서 $\lbrace \vec{x} \mid \vec{w}^{T}\vec{x}=b \rbrace$의 해집합은 $\mathbb{R}^{n-1}$에서 span할 것이다.
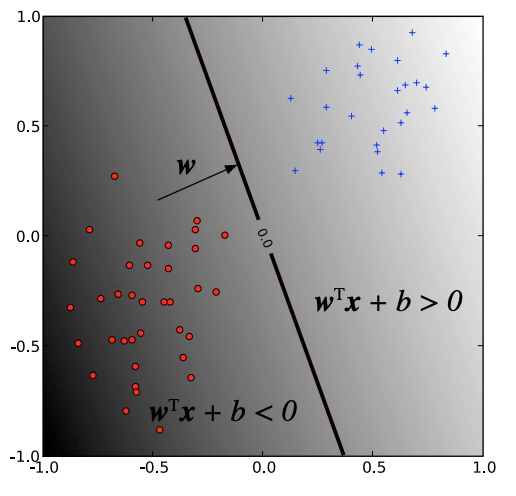
그림 1. Hyperplane
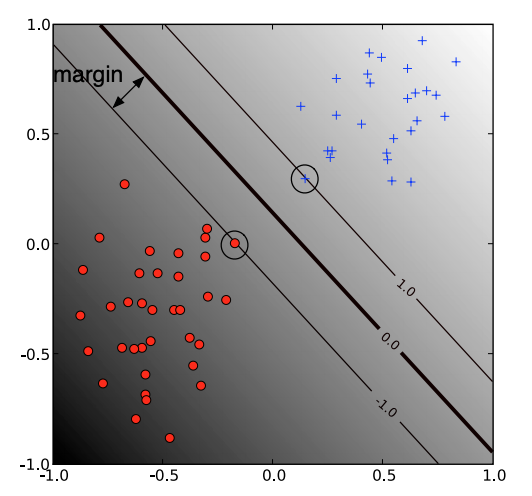
그림 2. Linear SVM with margin
Linear SVM은 $\mathbb{R}^{n}$상에 분포된 data point들과 그것을 가르는 hyperplane 사이의 margin(거리)을 최대화 하는 $\vec{w}$를 optimization 기법이다.
Optimization problem(find large margin)
임의의 hyperplane $\vec{w}^{T}\vec{x^+}=b$이 존재한다고 하자. 그리고 이 hyperplane을 $\pm$ 1만큼 translation하면,
$\vec{w}^{T}\vec{x^+}=b+1$
$\vec{w}^{T}\vec{x^-}=b-1$ 이 된다.
두 등식의 차이는 hyperplane들 사이의 width(거리)가 된다.
$\vec{w}^{T}\vec{x^+} - \vec{w}^{T}\vec{x^-} =2$
아래쪽 hyperplane과 위쪽 hyperplane의 거리는 equidistance이므로 절반으로 나누고 $\vec{w}$를 normalize하면,
$ = \frac{1}{2}\frac{\vec{w}^{T}}{\parallel w \parallel}(\vec{x^+}-\vec{x^-}) = \frac{1}{\parallel w \parallel}$, where $\frac{1}{\parallel w \parallel}$ is width(margin)
여기서 임의로 hyperplane을 $\pm$ 얼마만큼 translation을 하는지는 별로 중요하지 않다. 왜냐하면 $\parallel w \parallel$를 조절해서 얼마든지 이 값을 변화시킬 수 있기 때문이다.
Linear SVM은 이 width를 최대화 하는 것이므로 $\parallel w \parallel$를 최소화 해야한다. 따라서 다음과 같은 optimization problem이 된다.
$\underset{\vec{w},b}{\text{minimize}} \ \frac{1}{2}\parallel w \parallel^2$
$\text{subject to} \ y_{i}(\vec{w}^{T}\vec{x}_ {i}+b) \geq 1 , i=1,…,n$
$\frac{1}{2}\parallel w \parallel^2$는 $\parallel w \parallel$를 최소화하는 문제를 좀 더 손쉽게 풀기 위해서 변형한 형태이며 이렇게 변형해도 최소의 $\parallel w \parallel$를 찾는데에는 아무런 영향이 없다. 다시말해 $\parallel w \parallel$를 최소화 하는 문제는 $\frac{1}{2}\parallel w \parallel^2$를 최소화 하는 문제와 같다.
여기에 추가로 constraint를 추가하여 $y_{i}(\vec{w}^{T}\vec{x}_ {i}+b) \geq 1$라는 조건을 동시에 충족하여야 한다.
$y_{i}$는 classifier 다음과 같이 정의된다.
\[\ y_{i} = \begin{cases} 1 ,& \text{if } \ \vec{w}^{T}\vec{x}_ {i}+b \leq p \newline \newline -1, & \text{if } \ \vec{w}^{T}\vec{x}_ {i}+b > p \end{cases} \\]
$y_{i}$는 $\mathbb{R}^{n}$안의 data point $p$가 $\vec{w}^{T}\vec{x}_ {i}+b$ 기준으로 위쪽이거나 걸쳐 있을때 1의 값을 아래쪽일때 -1값을 가진다.
따라서 $y_{i}(\vec{w}^{T}\vec{x}_ {i}+b) \geq 1$가 되기 위해서는 $y_{i}$와 $\vec{w}^{T}\vec{x}_ {i}+b$가 둘다 음수거나 양수여야 한다. 그말은 해석하자면 $p$가 $\vec{w}^{T}\vec{x}_ {i}+b = -c$ 아래에 위치하거나 그렇지 않으면 $\vec{w}^{T}\vec{x}_ {i}+b = c$의 위에 위치해야 한다는 말이 된다.
만약 $\vec{w}^{T}\vec{x}_ {i}+b = -c$에 위치하면 $y_{i} = 1$이 되고 $\vec{w}^{T}\vec{x}_ {i}+b = -c$ 이므로 $y_{i}(\vec{w}^{T}\vec{x}_ {i}+b) = -c$ 음수가 된다. 반대로 $\vec{w}^{T}\vec{x}_ {i}+b = c$ 아래에 위치하면 $y_{i} = -1$ 이 되므로 $y_{i}(\vec{w}^{T}\vec{x}_ {i}+b)=-c$ 음수가 된다.
결과적으로 $y_{i}(\vec{w}^{T}\vec{x}_ {i}+b)\geq 1$가 함의하는 것은 $\vec{w}^{T}\vec{x}_ {i}+b = -c$ 와 $\vec{w}^{T}\vec{x}_ {i}+b = c$ 사이에는 data point가 존재하지 않아야 한다는 말과 같다.
Dual problem
위의 optimization problem을 lagrange dual function을 이용해 dual problem으로 치환해 풀 수 있다.(더 자세한 설명은 lagrange dual problem 포스팅 참조.)
Lagrange dual function은 다음과 같은 형태가 된다.
$g(\lambda) = \inf(\frac{1}{2}\parallel w \parallel^2 - \sum_{i=1}^{n}\lambda_{i}(y_{i}(\vec{w}^{T}\vec{x}_ {i}+b)-1))$
$= \inf(\frac{1}{2}\parallel w \parallel^2 - \sum_{i=1}^{n}(\lambda_{i} y_{i}\vec{w}^{T}\vec{x}_ {i}+\lambda_{i} y_{i}b-\lambda_{i}))$
다시, Lagrange daul function은 affine function들의 pointwise infimum 이므로 concave이다. 따라서 global optimal point가 존재한다. 그리고 optimal point는 기울기가 0이 되는 지점이다.
$w$에 대해 기울기가 0이되는 조건을 걸고 편미분 해주면,
$\nabla_{w}\frac{1}{2}\parallel w \parallel^2 - \sum_{i=1}^{n}(\lambda_{i} y_{i}\vec{w}^{T}\vec{x}_ {i}+\lambda_{i} y_{i}b-\lambda_{i}) = 0$
$ \iff w - \sum_{i=1}^{n} \lambda_{i} y_{i} \vec{x}_ {i} = 0$
$ \iff w = \sum_{i=1}^{n} \lambda_{i} y_{i} \vec{x}_ {i}$
$b$에 대해 기울기가 0이되는 조건을 걸고 편미분 해주면,
$\nabla_{b}\frac{1}{2}\parallel w \parallel^2 - \sum_{i=1}^{n}(\lambda_{i} y_{i}\vec{w}^{T}\vec{x}_ {i}+\lambda_{i} y_{i}b-\lambda_{i}) = 0$
$\iff \sum_{i=1}^{n}\lambda_{i} y_{i} = 0$
따라서,
$ w = \sum_{i=1}^{n} \lambda_{i} y_{i} \vec{x}_ {i}$ 와 $\sum_{i=1}^{n}\lambda_{i} y_{i} = 0$를 $g(\lambda)$에 대입해 주면
$\iff g(\lambda) = \frac{1}{2} \sum_{i=1}^{n}\sum_{j=1}^{n} \lambda_{i}\lambda_{j} y_{i}y_{j} {\vec{x}_ {i}}^{T}\vec{x}_ {j} - \sum_{i=1}^{n}\sum_{j=1}^{n}\lambda_{i}\lambda_{j} y_{i}y_{j}{\vec{x}_ {i}}^{T}{\vec{x}_ {j}} - \sum_{i=1}^{n}\lambda_{i} y_{i}b + \sum_{i=1}^{n} \lambda_{i} $
$\iff g(\lambda) = \sum_{i=1}^{n} \lambda_{i} - \frac{1}{2} \sum_{i=1}^{n}\sum_{j=1}^{n} \lambda_{i}\lambda_{j} y_{i}y_{j} {\vec{x}_ {i}}^{T}\vec{x}_ {j} - \sum_{i=1}^{n}\lambda_{i} y_{i}b $
$\iff g(\lambda) = \sum_{i=1}^{n} \lambda_{i} - \frac{1}{2} \sum_{i=1}^{n}\sum_{j=1}^{n} \lambda_{i}\lambda_{j} y_{i}y_{j} {\vec{x}_ {i}}^{T}\vec{x}_ {j}$
위의 결과를 토대로 아래와 같은 dual problem이 만들어 진다.
$\underset{\lambda>0}{\text{maximize}} \ \sum_{i=1}^{n} \lambda_{i} - \frac{1}{2} \sum_{i=1}^{n}\sum_{j=1}^{n} \lambda_{i}\lambda_{j} y_{i}y_{j} {\vec{x}_ {i}}^{T}\vec{x}_ {j}$
$\text{subject to} \ \sum_{i=1}^{n}\lambda_{i} y_{i} \geq 0 , i=1,…,n$
끝 아님… 뒤이어 작성 할 겁니다. :)